
Apache Spark
Before knowing what is Apache Spark, we need to understand what is Big Data and the challenges while working with Big data.
What is Big Data?
Big Data is just a term for the large volume of data which is growing exponentially with time. As we define the size of such data is very huge and complex that none of the traditional data management tools are able to store it or process it efficiently.
Challenges while working with Big Data
-
Data Storage
As we know the volume of data is huge and increasing exponentially on a daily basis. To handle it we need a storage system with increasing disk size and compressing the data using multiple machines, which are connected to each other and can share data efficiently.
-
Getting data from various systems
It is a tough task because of large volume and high velocity. There are millions of sources producing data with high speed. To handle this we need devices that can capture the data effectively and efficiently. For example, sensors that sense data in real-time and sends this information to the cloud for storage.
-
Analyzing and Querying data
The most difficult task in which not only retrieve the old data but also deal with insights in real-time. To handle this there are several options available. One option is increased processing speed using Distributed Computing. In Distributed computing first, need to build a network of machines or nodes known as “Cluster”. In Cluster, once the task arrives, it gets broken down into sub-tasks and distributes them to different nodes. Finally, aggregate the output of each node to the final output.
Apache Spark
Apache Spark was created at the University of California, Berkeley’s AMPLab in 2009. Later on, it was donated to the Apache Software Foundation. Apache Spark mostly written in Scala and some code Java. Apache Spark provides APIs for programmers which include Java, Scala, R, and Python. In simple words, Apache spark is cluster computing framework which supports in-memory computation for processing, querying and analyzing Big Data.
In-memory computation:
Apache Spark core concept is that it saves and loads the data in and from the RAM rather than from the Disk(Hard Drive). RAM has much higher processing speed than Hard Drive.That why Apache spark speed is 100 times faster than the Hadoop framework because of in-memory computation.
Note– Apache spark is not a replacement of Hadoop. It is actually designed to run on top of Hadoop.
Apache Spark Cluster-Overview:
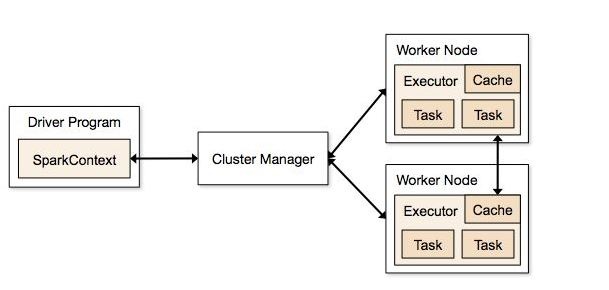
Image source: https://spark.apache.org/docs/1.1.1/img/cluster-overview.png
Spark Context : All Spark applications run as independent set of processes, coordinated by SparkContext in program. It holds a connection with Spark cluster manager.
Cluster Manager: Its job to allocates resources to each application in the driver program. Below are types of cluster managers supported by Apache Spark.
- Standalone
- Mesos
- YARN
Worker nodes: After SparkContext connects to the cluster manager, it starts assigning job to worker nodes on a cluster which works independently on each task and interact with each other.
Installation of Apache Spark on ubuntu:
1) Install Java
First check Java installed using “ java -version “
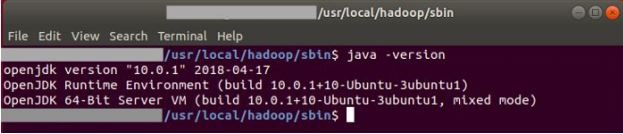
If not installed then follow run commands
sudo apt-get update
sudo apt-get install default-jdk
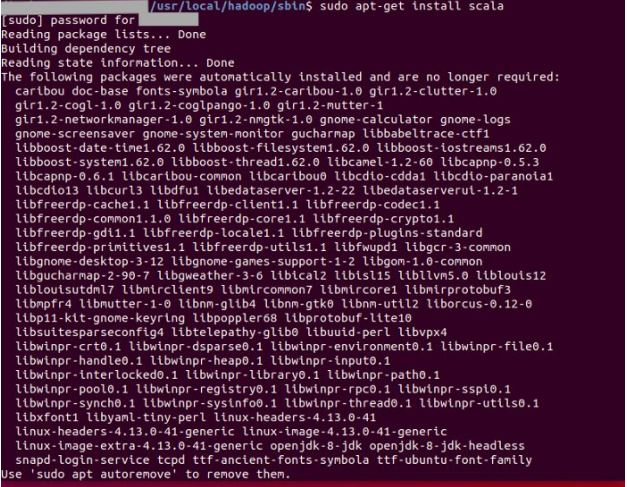
2) Install Scala
sudo apt-get install scala
To check type scala into your terminal:
scala
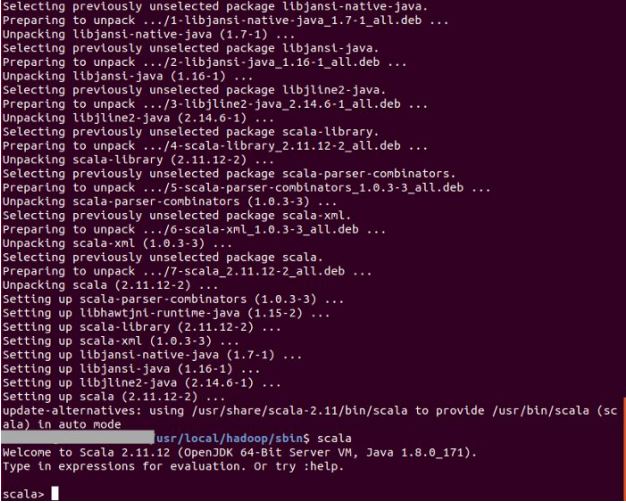
You should see the scala REPL running. Test it with:
println(“Hello World”)
You can then quit the Scala REPL with
:q
3) Install Spark
We need git for this, so in your terminal type:
sudo apt-get install git
Download latest Apache Spark and untar it
sudo tar xvf spark-2.3.1-bin-hadoop2.7.tgz -C /usr/local/spark
Add Spark path to bash file nano ~/.bashrc
Add below code snippet to the bash file
SPARK_HOME=/usr/local/spark
export PATH=$SPARK_HOME/bin:$PATH
Execute below command after editing the bashsrc
source ~/.bashrc

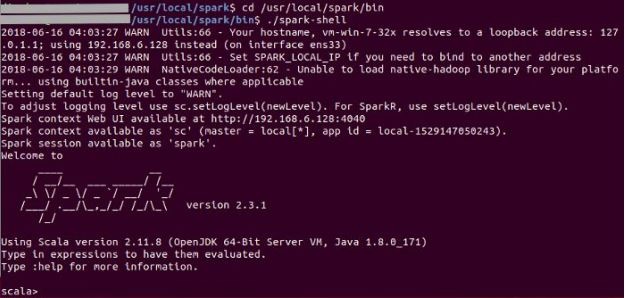
Go to the Bin Directory and execute the spark shell ./spark-shel
In the next article we will go deep dive in Apache Spark with coding example using scala.

